At WarpStream, we care a lot about the resiliency of our systems. Customers use our platform for critical workloads, and downtime needs to be minimal. Our standard clusters, which are backed by a single WarpStream control plane region, have a 99.99% availability guarantee with a durability comparable to that of our backing storage (DynamoDB / Amazon S3 in AWS, Spanner / GCS in GCP, and CosmosDB / Azure Blob Storage in Azure).
Today we're launching a new type of cluster, the Multi Region Cluster, which works exactly like a standard cluster but is backed by multiple control plane regions. Pairing this with a replicated data plane through the use of a quorum of 3 object storage buckets for writes allows any customer to withstand a full cloud provider region disappearing off the face of the earth, without losing a single ingested record or incurring more than a few seconds of downtime.
One of the interesting problems in distributed systems design is the fact that any of the pieces that compose the system might fail at any given point in time. Usually we think about this in terms of a disk or a machine rack failing in some datacenter that happened to host our workload, but failures can come in many shapes and sizes.
Individual compute instances failing are relatively common. This is the reason why most distributed workloads run with multiple redundant machines sharing the load, hence the word "distributed". If any of them fails the system just adds a new one in its stead.
As we go up in scope, failures get more complex. Highly available systems should tolerate entire sections of the infrastructure going down at once. A database replica might fail, or a network interface, or a disk. But a whole availability zone of a cloud provider might also fail, which is why they're called availability zones.
There is an even bigger failure mode that is very often overlooked: a whole cloud provider region can fail. This is both rare enough and cumbersome enough to deal with that a lot of distributed systems don't account for it and accept being down if the region they're hosted in is down, effectively bounding their uptime and durability to that of the provider's region.
But some WarpStream customers actually do need to tolerate an entire region going down. These customers are typically an application that, no matter what happens, cannot lose a single record. Of course, this means that the data held in their WarpStream cluster should never be lost, but it also means that the WarpStream cluster they are using cannot be unavailable for more than a few minutes. If it is unavailable for longer, there will be too much data that they have not managed to safely store in WarpStream and they might need to start dropping it.
.png)
Regional failures are not some exceptional phenomenon. A few days prior to writing (3rd of July 2025) DynamoDB had an incident that rendered the service irresponsive across the <span class="codeinline">us-east-1</span> region for 30+ minutes. Country-wide power outages are not impossible; some southern European countries recently went through a 12-hour power and connectivity outage.
System resiliency to failures is usually measured in uptime: the percentage of time that the system is responsive. You'll see service providers often touting four nines (99.99%) of uptime as the gold standard for cloud service availability.
System durability is a different measure, commonly seen in the context of storage systems, and is measured in a variety of ways. It is an essential property of any proper storage system to be extremely durable. Amazon S3 doesn't claim to be always available (their SLA kicks in after three 9’s), but it does tout eleven 9's of durability: you can count on any data acknowledged as written to not be lost. This is important because, in a distributed system, you might perform actions after a write to S3 is acknowledged that might be irreversible, and the write suddenly being rolled back is not an option, while the write transiently failing would simply trigger a retry in your application and life goes on.
The Recovery Point Objective is the point to which a system can guarantee to go back to in the face of catastrophic failure. An RPO of 10 minutes means the system can lose at most 10 minutes of data when recovering from a failure. When we talk about RPO=0 (Recovery Point Objective equals 0) we are essentially saying we are durable enough to promise that in WarpStream multi-region clusters, an acknowledged write is never going to be lost. In practice, this means that for a record to be lost, a highly available, highly durable system like Amazon S3 or DynamoDB would have to lose data or fail in three regions at once.
In WarpStream (like any other service), we have multiple sources of potential component failures. One of them is cloud service provider outages, which we've covered above, but the other obvious one is bad code rollouts. We could go into detail about the testing, reviewing, benchmarking and feature flagging we do to prevent rollouts from bringing down control plane regions, but the truth is there will always be a chance, however small, for a bad rollout to happen.
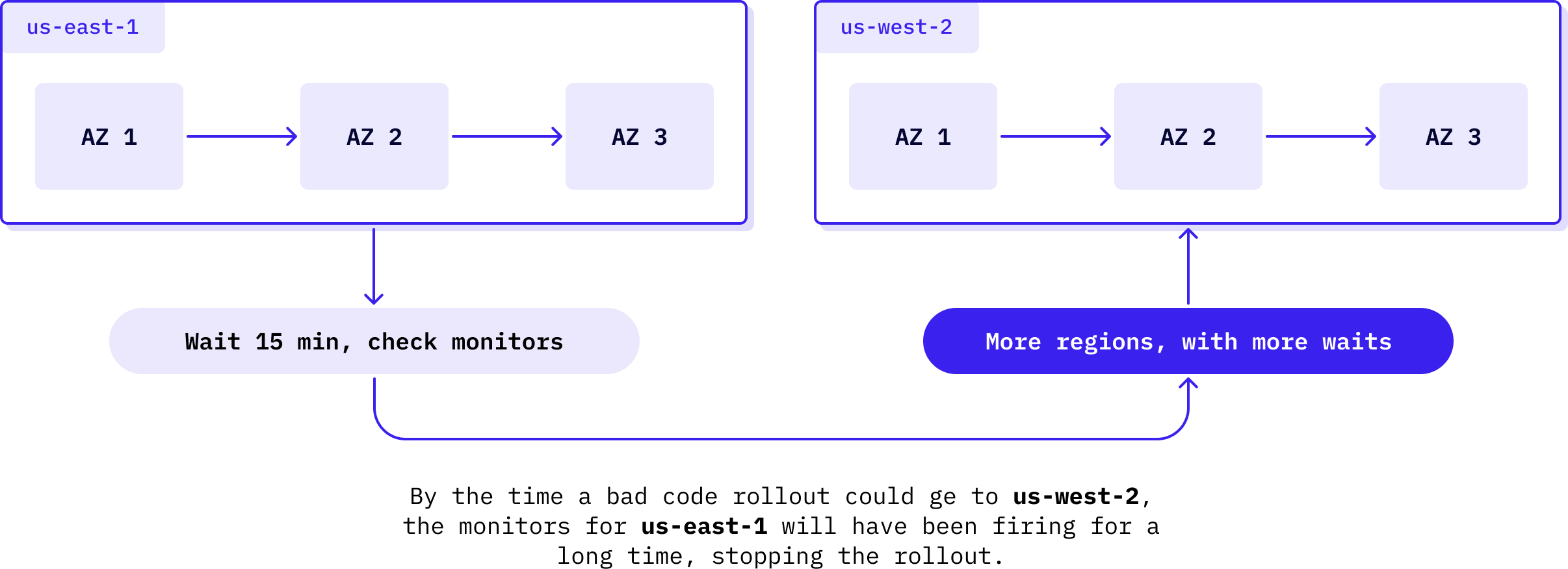
Within a single region, WarpStream always deploys each AZ sequentially so that a bad deploy will be detected and rolled back before affecting a region. In addition, we always deploy regions sequentially, so that even if a bad deploy makes it to all of the AZs in one region, it’s less likely that we will continue rolling it out to all AZs and all regions. Using a multi-region WarpStream cluster ensures that only one of its regions is deployed at a specific moment in time.
This makes it very difficult for any human-introduced bug to bring down any WarpStream cluster, let alone a multi-region cluster. With multi-region clusters, we truly operate each region of the control plane cluster in a fully independent manner: each region has a full copy of the data, and is ready to take all of the cluster's traffic at a moment's notice.
A multi-region WarpStream cluster needs both the data plane and the control plane to be resilient to regional failures. The data plane is operated by the customer in their environment, and the control plane is hosted by WarpStream, so they each have their own solutions.
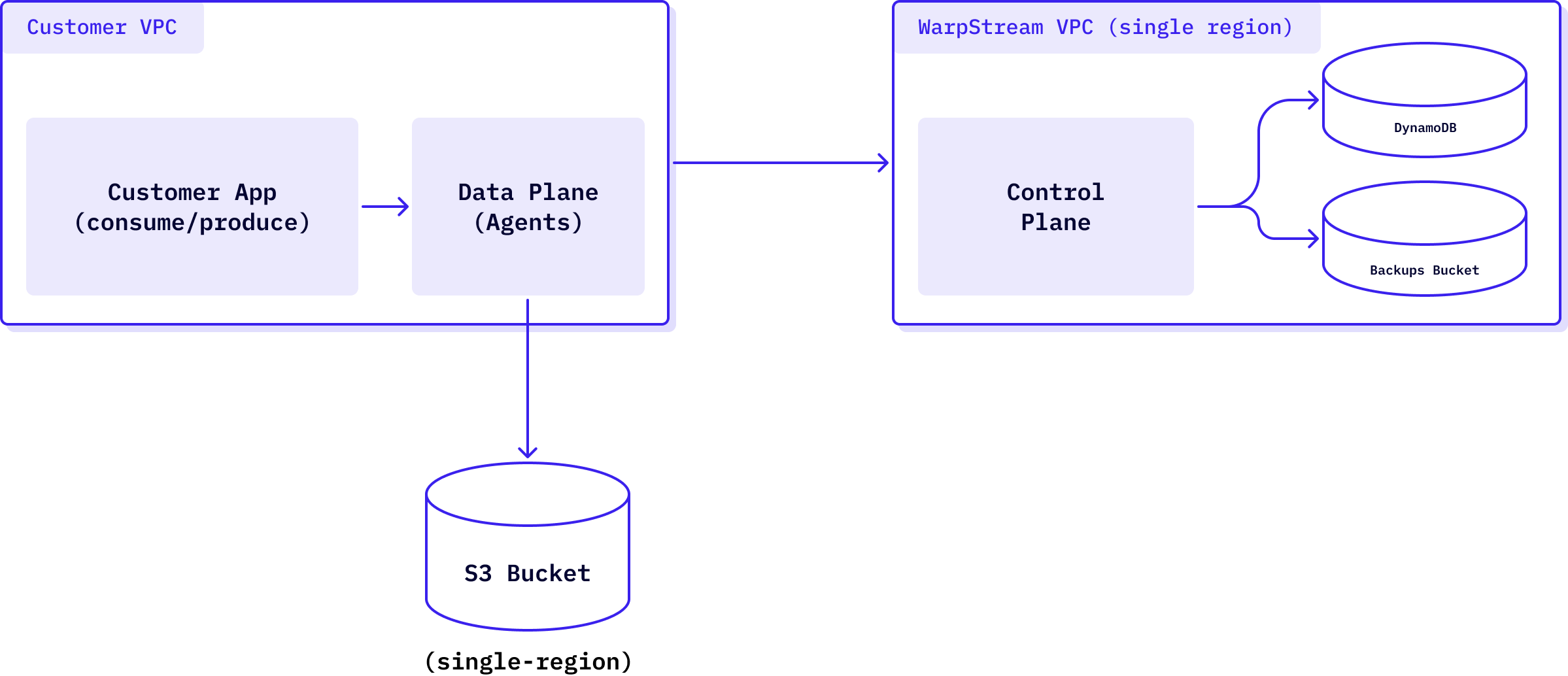
Thanks to previous design decisions, the data plane was the easiest part to turn into a multi-region deployment. Object storage buckets like S3 are usually backed by a single region. The WarpStream Agent supports writing to a quorum of three object storage buckets, so you can pick and choose any three regions from your cloud provider to host your data. This is a feature that we originally built to support multi-AZ durability for customers that wanted to use S3 Express One Zone for reduced latency with WarpStream, but it turned out to be pretty handy for multi-region clusters too.
Out of the gate you might think that this multi write overcomplicates things. Most cloud providers support bucket asynchronous replication for object storage after all. However, simply turning on bucket replication doesn’t work for WarpStream at all because the replication time is usually in minutes (specifically, S3 says 99.99% of objects are replicated within 15 minutes). To truly make writes durable and the whole system RPO=0 in case a region were to just disappear, we need at least a quorum of buckets to acknowledge the objects as written to consider it to be durably persisted. Systems that rely on asynchronous replication here will simply not provide this guarantee, let alone in a reasonable amount of time.
To understand how we made the WarpStream control planes multi-region, let's briefly go over the architecture of a control plane in a single region to understand how they work in multi-region deployments. We're skipping a lot of accessory components and additional details for the sake of brevity.
In the WarpStream control plane, the control plane instances are a group of autoscaled VMs that handle all the metadata logic that powers our clusters. They rely primarily on DynamoDB and S3 to do this (or their equivalents in other cloud providers – Spanner in GCP and CosmosDB in Azure).
Specifically, DynamoDB is the primary source of data and object storage is used as a backup mechanism for faster start-up of new instances. There is no cluster-specific storage elsewhere.
To make multi-region control planes possible without significant rearchitecture, we took advantage of the fact that the state storage became available as a multi-region solution with strong consistency guarantees. This is true for both AWS DynamoDB Global Tables which launched Multi-Region Strong Consistency recently and multi-region GCP SpannerDB which has always supported this.
As a result, converting our existing control planes to support multi-region was (mostly) just a matter of storing the primary state in multi-region Spanner databases in GCP and DynamoDB global tables in AWS. The control plane regions don’t directly communicate with each other, and use these multi-region tables to replicate data across regions.
.png)
Each region can read-write to the backing Spanner / DynamoDB tables, which means they are active-active by default. That said, as we’ll explain below, it’s much more performant to direct all metadata writes to a single region.
Though the architecture allows for active-active dual writing on different regions, doing so would introduce a lot of latency due to conflict resolution. On the critical path of a request in the write path, one of the steps is committing the write operation to the backing storage. Doing so will be strongly consistent across regions, but we can easily see how two requests that start within the same few milliseconds targeting different regions will often have one of them go into a rollback/retry loop as a result of database conflicts.
.png)
Temporary conflicts when recovering from a failure is fine, but a permanent state with a high number of conflicts would result in a lot of unnecessary latency and unpredictable performance.
We can be smarter about this though, and the intuitive solution works for this case: We run a leader election among the available control planes, and we make a best effort attempt to only direct metadata traffic from the WarpStream Agents to the current control plane leader. Implementing multi-region leader election sounds hard, but in practice it’s easy to do using the same primitives of Spanner in GCP and DynamoDB global tables in AWS.
.png)
We can optimize a lot of things in life but the speed of light isn't one of them. Cloud provider regions are geolocated in a specific place, not only out of convenience but also because services backed by them would start incurring high latencies if virtual machines that back a specific service (say, a database) were physically thousands of kilometers apart. That’s because the latency is noticeable even using the fastest fiber optic cables and networking equipment.
DynamoDB single-region tables and GCP spanner both proudly offer sub 5ms latency for read and write operations, but this latency doesn't hold in multi-region tables with strong consistency. They require a quorum of backing regions to acknowledge the write before accepting it, so there are roundtrips across regions involved. DynamoDB multi-region also has the concept of a leader which must know about all writes, which must always be part of the quorum, making the situation even more complex to think about.
Let's look at an example. These are the latencies between different DynamoDB regions in the first configuration we’re making available:
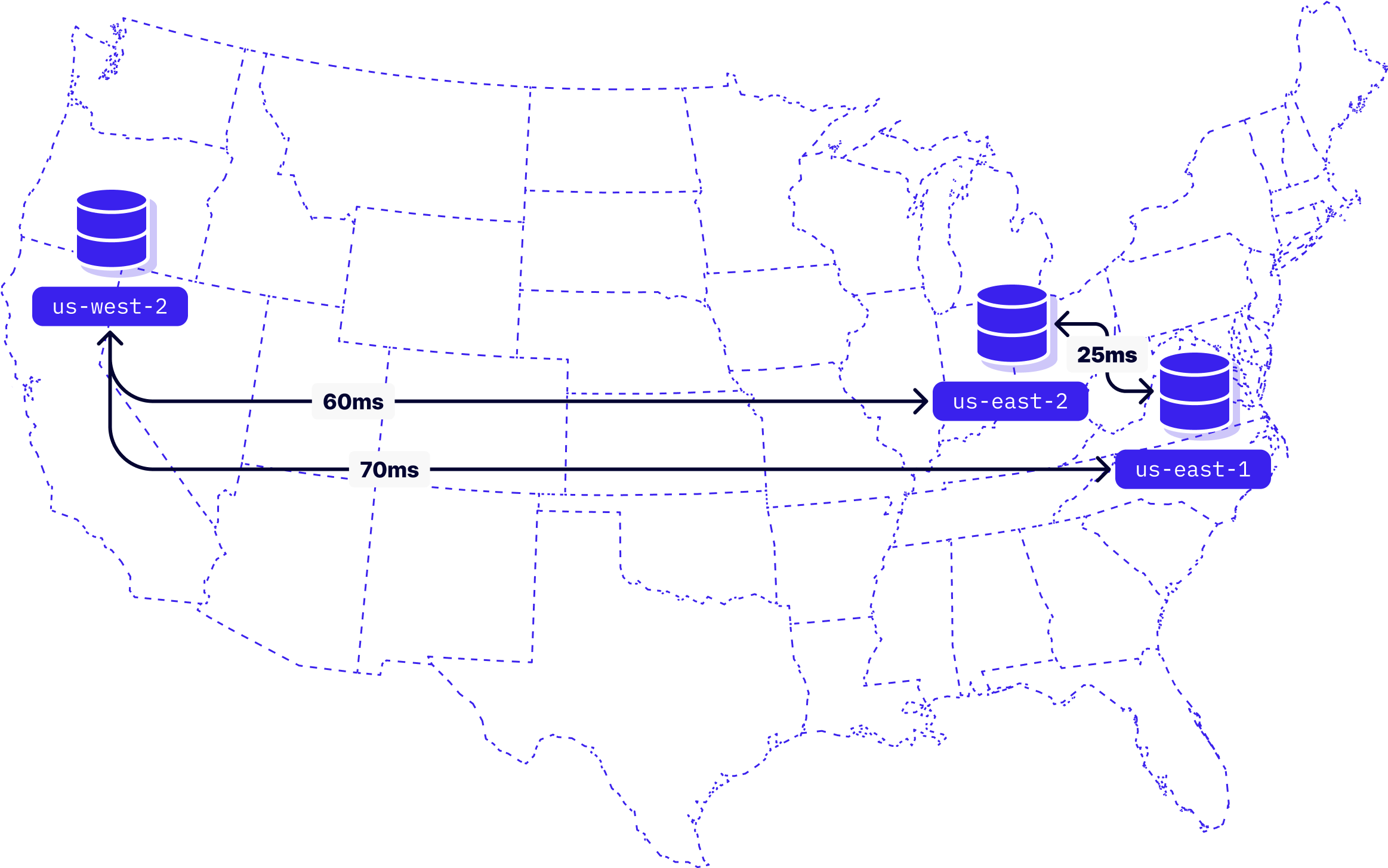
Since DynamoDB writes always need a quorum of regions to acknowledge, we can easily see that writing to <span class="codeinline">us-west-2</span> will be on average slower than writing to <span class="codeinline">us-east-1</span>, because the latter has another region (<span class="codeinline">us-east-2</span>) closer by to achieve quorum with.
This has a significant impact on the producer and end to end latency that we can offer for this cluster. To illustrate this, see the 100ms difference in producer latency for this benchmark cluster which is constantly switching WarpStream control plane leadership from <span class="codeinline">us-east-1</span> to <span class="codeinline">us-west-2</span> every 30 minutes.
.png)
The latency you can expect from multi-region WarpStream clusters is usually within 80-100ms higher (p50) than a single-region cluster equivalent, but this depends a lot on the specific set of regions .
To deal with these latency concerns in a way that is easy to manage, we offer a special setting which can declare one of the WarpStream regions as "preferred". The default setting for this is `auto`, which will dynamically track control plane latency across all regions and rig the elections so that (if responsive) the region with the lowest average latency wins and the cluster is overall more performant.
If for whatever reason you need to override this - for example, you want to co-locate metadata requests and agents, or there is an ongoing degradation in the current leader- you can also deactivate auto mode and choose a preferred leader.
If the preferred leader ever goes down, one of the "follower" regions will take over, with no impact for the application.
Let's do a recap and put it to the test: In a multi-region cluster, we’ll have one of multiple regional control planes acting as the leader, with all agents sending traffic to it. The rest will be simply keeping up, ready to take over. If we bring one of the control planes down by instantly scaling the deployment to 0, let's see what happens:
.png)
The producers never stopped producing. We see a small latency spike of around 10 seconds but all records end up going through, and all traffic is quickly redirected to the new leader region.
Importantly, no data is lost between the time that we lost the leader region and the time that the new leader region was elected. WarpStream’s quorum-based ack mechanism ensures both data and metadata were durably persisted in multiple regions before providing an acknowledgement to the client, the client was able to successfully retry any batches that were written during the leader election.
We lost an entire region, and the cluster kept functioning with no intervention from anyone. This is the definition of RPO=0.
Hard failures where everything in a region is down are the easier scenarios to recover from. If an entire region just disappears, the others will easily take over and things will keep running smoothly for the customer. More often though, the failures are only partial: one region suddenly can’t keep up, latencies increase, backpressure kicks in and the cluster starts being degraded but not entirely down. There is a grey area here where the system (if self-healing) needs to determine that a given region is no longer “good enough” for leadership and defect to another.
In our initial implementation, we recover from partial failures in the form of increased latency from the backing storage. If some specific operations take too long on one region, we will automatically choose another as preferred. We also have the manual override in place in case we fail to notice a soft failure and we want to quickly switch leadership. There is no need to over-engineer more at first. As we see more use-cases and soft failure modes, we will keep updating our criteria for switching leadership and away from degraded regions.
For now we’re launching this feature in Early Access mode with targets in AWS regions. Please reach out if interested and we’ll work with you to get you in the Early Access program. During the next few weeks we’ll also roll out targets in GCP regions. We’re always open to creating new targets (sets of regions) for customers that need them.
We will also work on making this setup even cheaper, by helping agents co-locate reads with their current region and reading from the co-located object storage bucket if there is one in the given configuration.
WarpStream clusters running in a single region are already very resilient. As described above, within a single region the control plane and metadata are replicated across availability zones, and that’s not new. We have always put a lot of effort into ensuring their correctness, availability and durability.
With WarpStream Multi-Region Clusters, we can now ensure that you will also be protected from region-wide cloud provider outages, or single-region control plane failures.
In fact, we are so confident in our ability to protect against these outages that we are offering a 99.999% uptime SLA for WarpStream Multi-Region Clusters. This means that the downtime threshold for SLA service credits is 26 seconds per month.
WarpStream’s standard single-region clusters are still the best option for general purpose cost-effective streaming at any scale. With the addition of Multi-Region Clusters, WarpStream can now handle the most mission-critical workloads, with an architecture that can withstand a complete failure of an entire cloud provider region with no data loss, and no manual failover.
