Orbit is a tool which creates identical, inexpensive, scaleable, and secure continuous replicas of Kafka clusters.
It is built into WarpStream and works without any user intervention to create WarpStream replicas of any Apache Kafka-compatible source cluster like open source Apache Kafka, WarpStream, Amazon MSK, etc.
Records copied by Orbit are offset preserving. Every single record will have the same offset in the destination cluster as it had in the source cluster, including any offset gaps. This feature ensures that your Kafka consumers can be migrated transparently from a source cluster to WarpStream, even if they don’t store their offsets using the Kafka consumer group protocol.

There are existing tools in the Kafka ecosystem for replication, specifically MirrorMaker. So why did we build something new?
Orbit solves two big problems that MirrorMaker doesn’t – it creates perfect replicas of source Kafka clusters (for disaster recovery, performant tiered storage, additional read replicas, etc.), and also provides an easy migration path from any Kafka-compatible technology to WarpStream.
Existing tools in the ecosystem like MirrorMaker are not offset preserving[1]. Instead, MirrorMaker creates and maintains an offset mapping which is used to translate consumer group offsets from the source cluster to the destination cluster as they’re copied. This offset mapping is imprecise because it is expensive to maintain and cannot be stored for every single record.

Offset mapping and translation in MirrorMaker has two problems:
This means that tools like MirrorMaker can’t be used to safely migrate every Apache Kafka application from one cluster to another.
Orbit, on the other hand, is offset preserving. That means instead of maintaining an offset mapping between the source and destination cluster, it ensures that every record that is replicated from the source cluster to the destination one maintains its exact offset, including any offset gaps. It’s not possible to do this using the standard Apache Kafka protocol, but since Orbit is tightly integrated into WarpStream we were able to accomplish it using internal APIs.
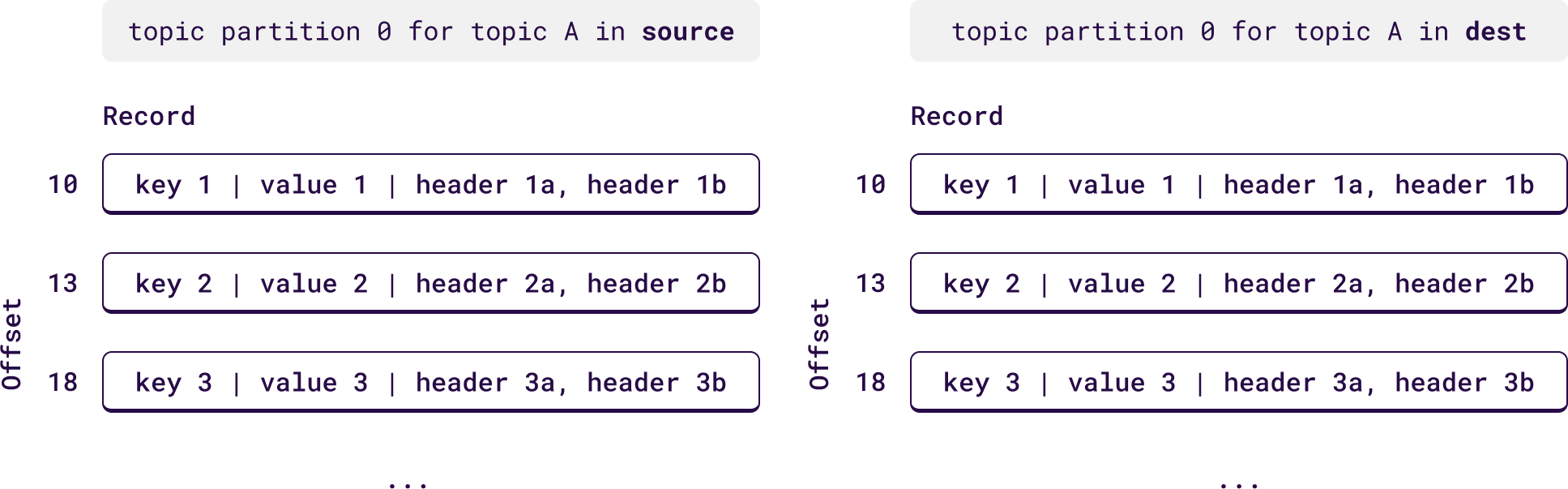
This solves the two problems with MirrorMaker. Since Orbit ensures that the offset of every single record written to the destination has exactly the same offset as the source, consumer group offsets from the source can be copied over without any translation.
Moreover, applications which store offsets outside of the consumer group protocol can still switch consumption from the source cluster to WarpStream seamlessly because the offsets they were tracking outside of Kafka map to the exact same records in WarpStream that they mapped to in the source cluster.
In summary, offset-preserving replication is awesome because it eliminates a huge class of Apache Kafka replication edge cases, so you don’t have to think about them.

Orbit is fully integrated with the rest of WarpStream. It is controlled by a stateless scheduler in the WarpStream control plane which submits jobs which are run in the WarpStream Agents. Just like the rest of WarpStream, the metadata store is considered the source of truth and the Agents are still stateless and easy to scale.
You don’t need to learn how to deploy and monitor another stateful distributed system like MirrorMaker to perform your migration. Just spin up WarpStream Agents, edit the following YAML file in the WarpStream Console, hit save, and watch your data start replicating. It’s that easy.
To make your migrations go faster, just increase the source cluster fetch concurrency from the YAML and spin up more stateless WarpStream Agents if necessary.
Click ops not your cup of tea? You can use our terraform provider or dedicated APIs instead.
Customers building applications using Kafka shouldn't have to worry that they haven't considered every single replication edge case, so we obsessively thought about correctness and dealt with edge cases that come up during async replication of Kafka clusters.
As a quick example, it is crucial that the committed consumer group offset of a topic partition copied to the destination is within the range of offsets for the topic partition in the destination. Consider the following sequence of events which can come up during async replication:
To ensure that we catch other correctness issues of this nature, we built a randomized testing framework that writes records, updates the data and metadata in a source cluster, and ensures that Orbit keeps the source and destination perfectly in sync.
As always, we sweat the details so you don’t have to!
Once you have a tool which you can trust to create identical replicas of Kafka clusters for you, and the destination cluster is WarpStream, the following use cases are unlocked:
Orbit keeps your source and destination clusters exactly in sync, copying consumer group offsets, topic configurations, cluster configurations, and more. The state in the destination cluster is always kept consistent with the source.
Orbit can, of course, be used to migrate consumers which use the Consumer Group protocol, but since it is offset preserving it can also be used to migrate applications where the Kafka consumer offsets are stored outside of the source Kafka cluster.
Since the source and destination clusters are identical, you can temporarily cut over your consumers to the destination WarpStream cluster if the source cluster is unavailable.
The destination WarpStream cluster can be in another region from your source cluster to achieve multi-region resiliency.
Replicating your source clusters into WarpStream is cheaper than replicating into Apache Kafka because WarpStream’s architecture is cheaper to operate:
This means that you can use the WarpStream cluster replica to offload secondary workloads to the WarpStream cluster to provide workload isolation for your primary cluster.
We’ve written previously about some of the issues that can arise when bolting tiered storage on after the fact to existing streaming systems, as well as how WarpStream mitigates those issues with its Zero Disk Architecture. One of the benefits of Orbit is that it can be used as a cost effective tiered storage solution that is performant and scalable by increasing the retention of the replicated topics in the WarpStream cluster to be higher than the retention in the source cluster.
Orbit is available for any BYOC WarpStream cluster. You can go here to read the docs to see how to get started with Orbit, learn more via the Orbit product page, or contact us if you have questions. If you don’t have a WarpStream account, you can create a free account. All new accounts come pre-loaded with $400 in credits that never expire and no credit card is required to start.
Notes
[1] While Confluent Cluster Linking is also offset preserving it cannot be used for migrations into WarpStream.
